
「知っている」と「知ったかぶり」の違い - マルチLLM合議による知識検証システム
はじめに
「銀河鉄道の夜について知ってる?」
この質問に対して、AIは「銀河鉄道の夜」について答えるべきです。しかし以前のYuiは、こう解釈してしまうことがありました:
主題: 「銀河鉄道の夜について知」
「知ってる」の「って」を引用マーカーと誤認し、主題を途中で切ってしまう——聞こえているのに、正しく聴けていない問題です。
今日は、この「言葉の聴き取り精度」を高めるRawInput抽象化と、さらに一歩進んで複数のAIで知識を検証するマルチLLM合議システムの設計についてお話しします。
「って」の二面性を見抜く
形態素解析による用法判定
日本語の「って」には、大きく分けて2つの用法があります:
| 用法 | 例文 | 「って」の役割 |
|---|---|---|
| 引用マーカー | 「AIって何?」 | 「AI」というトピックを提示 |
| 動詞活用形 | 「知ってる?」 | 「知る」の促音便接続 |
従来のパターンマッチングでは、この区別ができませんでした。「って」を見つけたら一律に「その前が主題」と判断してしまい、「知」が主題になってしまう。
解決策は形態素解析です。文を品詞レベルで分解し、「って」の直前が動詞なのか名詞なのかを判定します:
「銀河鉄道の夜について知ってる?」 ↓ 形態素解析 [銀河鉄道の夜] [について] [知っ(動詞)] [てる] [?] ↓ 判定 「知っ」は動詞 → 「って」は動詞活用形の一部 「について」の前が主題 → 「銀河鉄道の夜」
これにより、言葉の構造を理解した上での主題抽出が可能になりました。
知識の「信頼性」という課題
ハルシネーションの恐怖
主題を正しく抽出できても、次の問題が待っています——AIは平気で嘘をつく。
いわゆる「ハルシネーション(幻覚)」です。存在しない事実を、あたかも知っているかのように語ってしまう。これは単一のLLMに頼る限り、避けられない問題でした。
人間社会の知恵:合議制
では、人間社会はどうやって「正しい知識」を担保してきたのでしょうか?
答えは複数の視点からの検証です。学術論文の査読、裁判の合議制、科学における追試——一人の意見を鵜呑みにせず、複数の独立した判断を突き合わせる。
この知恵をAIに応用したのが、マルチLLM合議システムです。
マルチLLM合議の設計
複数の「知性」に問う
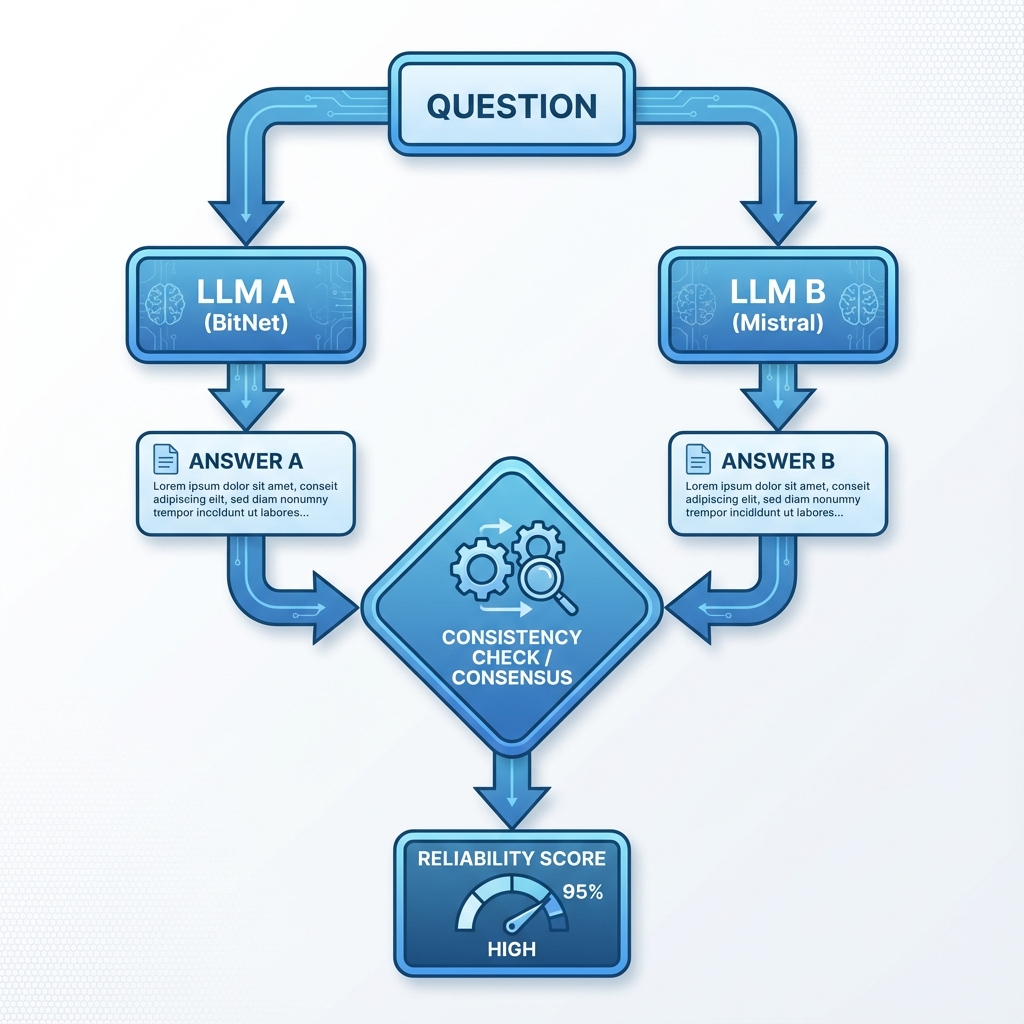
同じ質問を複数のLLMに投げ、回答を比較します。もし複数のモデルが同じ内容を答えれば、それは信頼できる知識である可能性が高い。
一致度の測定
回答の一致度は、3つの観点から評価します:
| 観点 | 手法 | 重み |
|---|---|---|
| キーワード一致 | 名詞抽出 + Jaccard係数 | 40% |
| 意味的類似度 | 埋め込みベクトルのコサイン類似度 | 60% |
| 矛盾検出 | 否定表現の有無チェック | 拒否権 |
矛盾が検出された場合は、一致度に関わらず「信頼できない」と判定します。
Webサーチより信頼できる理由
「なぜWeb検索ではなくLLM合議なのか?」という疑問があるかもしれません。
| 観点 | Web検索 | マルチLLM合議 |
|---|---|---|
| ソース品質 | 玉石混交 | 学習データが品質管理済み |
| 一貫性 | サイトごとにバラバラ | 複数LLMで裏付け |
| オフライン | 不可 | 可能 |
Webは誰でも書けます。しかしLLMの学習データは、ある程度の品質フィルタリングを経ています。複数の独立したLLMが同じ答えを出すということは、複数の学習データソースで裏付けがあるということです。
ライセンスという制約を超えて
出力は捨てる、知識だけ残す
ここで一つ、技術的な制約があります。LLMのライセンスです。
Llama-3やQwenなど、高性能なモデルの多くは「出力を使って別のAIを訓練すること」を禁止しています。では、これらのモデルは使えないのでしょうか?
答えは工夫次第です:
graph TD
L[LLM出力] --> K[キーワード抽出]
K --> S[Webサーチ実行]
S --> D[全て破棄]
S -- 検索結果 --> W[正規ソースから学習]
style D fill:#f9f,stroke:#333,stroke-width:2px
LLMの出力そのものは学習に使わず、得られたキーワードは一時的な検索クエリとして使用し、即座に破棄します。最終的な知識は、公式APIを通じてオープンコンテンツから取得します。
おわりに
「知っている」と「知ったかぶり」の違いは、検証可能性にあります。
一人の証言より、複数の独立した証言。一つのソースより、複数のソースからの裏付け。人間社会が長い歴史の中で培ってきた「信頼性担保の知恵」を、AIにも組み込む。
Yuiは単に「答えを返す」のではなく、「なぜそれが正しいと言えるのか」を自ら検証できるAIを目指しています。今日の設計は、その重要な一歩です。
次のステップでは、実際にマルチLLM環境を構築し、合議システムの精度を検証していきます。