
純RustでローカルLLM!Candle + BitNetで爆速推論
2026年1月9日
はじめに
「ローカルでLLM動かしたいけど、Ollamaだと別プロセス立てないといけないし、HTTPでやり取りするの面倒...」
そんな悩みを解決する方法を見つけました。HuggingFace Candle + BitNet という組み合わせなら、純Rust・HTTP不要・async不要でLLM推論ができるんです。
従来のローカルLLM構成の課題
Ollama方式の問題点
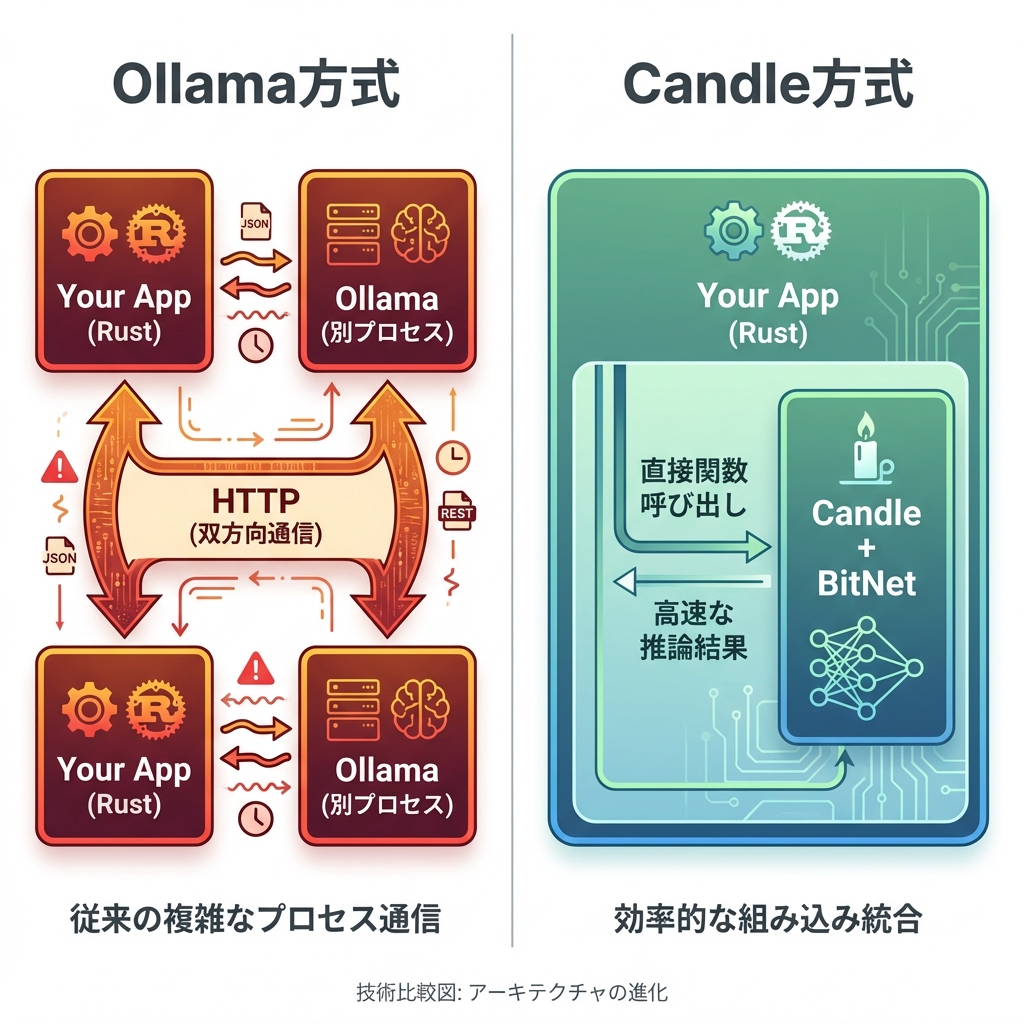
従来のOllama方式では、以下のような課題がありました:
- 別プロセスの管理が必要 - Ollamaサーバーを常時起動しておく必要がある
- HTTP通信のオーバーヘッド - ローカルホストとはいえ、HTTPプロトコルの処理が発生
- Rustからの呼び出しがasyncになる - 非同期処理の複雑さが増す
- エラーハンドリングが複雑化 - ネットワークエラー、タイムアウトなど考慮事項が増える
理想の構成
一方、Candle + BitNetを使えば:
- 単一プロセス - アプリケーションに組み込み
- 関数呼び出しで推論 - シンプルな同期呼び出し
- async不要 - 通常の関数として扱える
- 型安全 - Rustの型システムの恩恵を受けられる
HuggingFace Candleとは
概要
CandleはHuggingFaceが開発するRust製の軽量MLフレームワークです。
| 項目 | 詳細 |
|---|---|
| 開発元 | HuggingFace |
| 言語 | 純Rust(FFI不要) |
| 対応モデル | 130以上(LLaMA, Phi, Gemma, Mistral等) |
| 量子化 | Q2K〜Q8K(GGML/GGUF形式) |
| バックエンド | CPU, CUDA, Metal |
なぜCandleを選ぶのか
- 純Rust: C++バインディング不要、ビルドが簡単
- 軽量: PyTorchのような巨大依存なし
- safetensors対応: HuggingFace Hubから直接読み込み
- SIMD最適化: AVX, NEON対応で高速
BitNet 1.58bitの革新
従来の量子化 vs BitNet

従来の量子化(INT8等)では、重みを-128〜+127の256段階で表現し、整数乗算が必要でした。
しかし BitNet 1.58bit では、重みを{-1, 0, +1}の3値のみで表現します!
なぜ「乗算不要」なのか
重みが3値しかないため、乗算を以下のように単純化できます:
- weight = -1 の場合:
-1 × x = -x(符号反転するだけ) - weight = 0 の場合:
0 × x = 0(スキップ) - weight = +1 の場合:
+1 × x = x(そのまま)
つまり、浮動小数点乗算(重い)→ 整数の加減算(軽い)に変換できるのです!
パフォーマンス
Bit-TTTの実績
| 指標 | 数値 |
|---|---|
| 推論速度 | 60,000 tokens/sec |
| 使用ハード | CPU only(GPU不要) |
| メモリ | 通常LLMの1/10以下 |
この驚異的な速度は、BitNetのternary量子化がSIMD命令と相性抜群だからです。
ユースケース
向いている用途
- エッジデバイスでの推論 - GPU不要で動作
- Rustアプリケーションへの組み込み - 依存関係がシンプル
- レイテンシ重視のリアルタイム処理 - HTTP通信のオーバーヘッドなし
- オフライン環境での動作 - 外部サーバー不要
具体例:意図解析への応用
例えば、ユーザーの発言から主題を抽出する処理を考えてみましょう。
「青空文庫って知ってる?」という入力から「青空文庫」を主題として抽出したい場合、Candleを使えば同期的な関数呼び出しで実現できます。タイポがあっても、LLMの柔軟性で対応可能です。
まとめ
| 項目 | Ollama | Candle + BitNet |
|---|---|---|
| プロセス | 別プロセス | インプロセス |
| 通信 | HTTP | 関数呼び出し |
| async | 必要 | 不要 |
| 依存 | 外部バイナリ | Cargoのみ |
| 速度 | 1,000 tok/s | 60,000 tok/s |
純Rust・HTTP不要・async不要でローカルLLM推論を実現!
Candle + BitNetの組み合わせは、Rustアプリケーションに機械学習を組み込む新しい選択肢として、非常に魅力的です。
参考リンク
※この記事はYui AIプロジェクトでの技術検討をもとに作成しました