
形態素解析の限界とLLMによる主題抽出
2026年1月10日
日本語の自然言語処理で必ず使う「形態素解析」。MeCabやVibratoは高速で便利ですが、複合語や固有名詞の扱いに限界があります。
「青空文庫にはどんな書籍がある?」という質問が正しく処理できない...そんな経験はありませんか?
この記事では、形態素解析の限界と、それをLLMで補完する新しいアプローチを紹介します。
1. 問題:複合語が分割される
実際に起きた問題
入力: 「青空文庫にはどんな書籍がある?」
期待: 主題 = "青空文庫"
実際: 主題 = None(抽出失敗)
なぜ失敗したのか?
形態素解析の結果
MeCab/Vibrato による解析:
青空 | 名詞,一般
文庫 | 名詞,一般
に | 助詞,格助詞
は | 助詞,係助詞
どんな | 連体詞
書籍 | 名詞,一般
が | 助詞,格助詞
ある | 動詞,自立
? | 記号,一般
「青空文庫」が「青空」+「文庫」に分割されてしまう!
分割される理由
形態素解析器は辞書に登録された単語を基準に分割します。
- 「青空」→ 辞書にある → 1トークン
- 「文庫」→ 辞書にある → 1トークン
- 「青空文庫」→ 辞書にない → 分割される
2. 従来の対処法とその問題
対処法1: パターンマッチング
// ❌ アンチパターン
fn extract_subject(input: &str) -> Option<String> {
if let Some(pos) = input.find("にはどんな") {
return Some(input[..pos].to_string());
}
if let Some(pos) = input.find("とは") {
return Some(input[..pos].to_string());
}
if let Some(pos) = input.find("って") {
return Some(input[..pos].to_string());
}
// パターンが際限なく増える...
None
}
問題点:
- パターンが際限なく増える
- 英語に対応できない
- 新しい表現に対応できない
- ソースコードが肥大化
対処法2: ユーザー辞書に固有名詞を追加
# user_dict.csv
青空文庫,名詞,固有名詞,アオゾラブンコ
Wikipedia,名詞,固有名詞,ウィキペディア
GitHub,名詞,固有名詞,ギットハブ
問題点:
- タイポに対応できない!
「青空文庫って知ってる?」→ OK
「青空分岐って知ってる?」→ NG(タイポ)
解析結果:
青空 | 名詞
分岐 | 名詞 ← 完全に別の単語として認識
ユーザーは必ずタイポする。辞書登録では対応できない。
3. 根本的な問題
形態素解析の限界
| 特性 | 形態素解析 |
|---|---|
| 処理方式 | ルールベース(辞書+コスト計算) |
| 未知語 | 分割されるか、1文字ずつ認識 |
| タイポ | 対応不可 |
| 文脈理解 | なし |
形態素解析は**「文字列をどう分割するか」を決めるツールであり、「何が主題か」**を理解するツールではない。
必要なのは「理解」
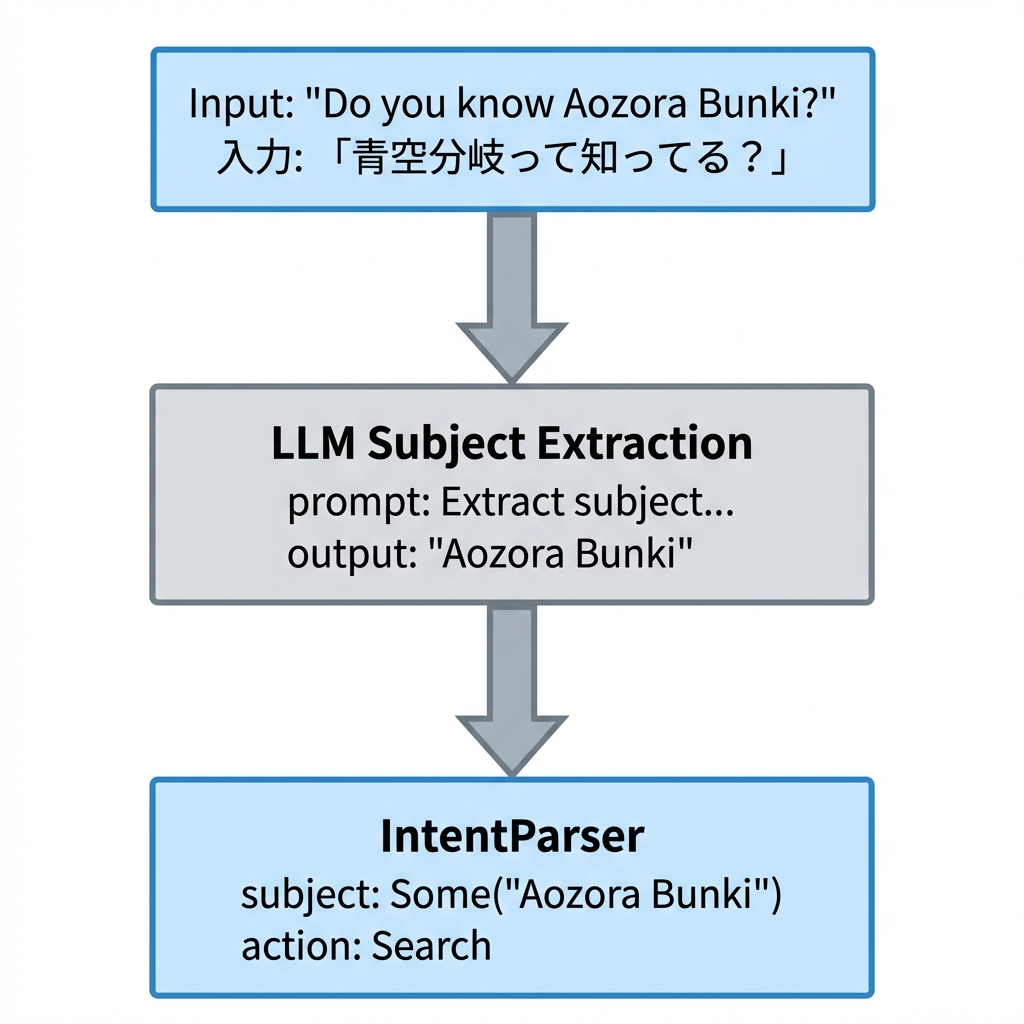
入力: 「青空分岐って知ってる?」(タイポ)
人間の理解:
- 「青空分岐」は何かの名前っぽい
- 「って知ってる?」は質問パターン
- 主題は「青空分岐」だろう
- (もしかして「青空文庫」のこと?)
形態素解析の理解:
- 「青空」名詞
- 「分岐」名詞
- 主題は... わからない
4. LLMによる主題抽出
アプローチ
形態素解析の前段階でLLMを使い、主題を抽出する。
なぜLLMなら対応できるのか
| 特性 | 形態素解析 | LLM |
|---|---|---|
| 処理方式 | ルールベース | 統計的パターン認識 |
| 未知語 | 分割される | 文脈から推測 |
| タイポ | 対応不可 | 柔軟に対応 |
| 文脈理解 | なし | あり |
LLMは「見たことない単語」でも、文脈から「これが主題だろう」と推測できる。
5. 実装戦略
構成
struct IntentParser {
tokenizer: VibratoTokenizer, // 従来の形態素解析
subject_extractor: BitNetModel, // LLM主題抽出(新規)
}
impl IntentParser {
fn parse(&self, input: &str) -> Intent {
// Step 1: LLMで主題抽出(タイポ耐性あり)
let subject = self.subject_extractor.extract(input);
// Step 2: 形態素解析で補助情報取得
let tokens = self.tokenizer.tokenize(input);
let action = self.detect_action(&tokens);
Intent {
subject: Some(subject),
action,
confidence: 0.9,
}
}
}
なぜBitNet?
- ローカル実行: プライバシー保護、オフライン対応
- 高速: 60,000 tokens/sec(CPU only)
- 軽量: 通常LLMの1/10以下のメモリ
- 純Rust: HTTP不要、async不要
詳細は別記事「純RustでローカルLLM!Candle + BitNetで爆速推論」参照。
6. ハイブリッドアプローチの利点
形態素解析を捨てない
LLMだけに頼らず、形態素解析も併用する理由:
- 品詞情報: 動詞・名詞の区別はルールベースが確実
- 処理速度: 単純なケースは形態素解析の方が速い
- 省リソース: LLMを呼ぶ必要がないケースを判別
- 辞書活用: JMDict等の構造化知識を活用
役割分担
7. 今後の展望
辞書学習との連携
1. LLMで「青空分岐」を主題として抽出
2. 検索結果から「青空文庫」が正しいと判明
3. 「青空文庫」をユーザー辞書に自動登録
4. 次回から形態素解析だけで対応可能に
LLMの結果を辞書にフィードバックし、システム全体が賢くなる。
まとめ
| アプローチ | 長所 | 短所 |
|---|---|---|
| 形態素解析のみ | 高速、決定的 | 未知語・タイポに弱い |
| パターンマッチ | 実装簡単 | スケールしない |
| 辞書追加 | 確実 | タイポ対応不可 |
| LLM + 形態素 | 柔軟、タイポ対応 | やや複雑 |
形態素解析の限界を認識し、LLMで補完するのが現実的な解決策。