
AI学習フェーズ設計 - 受動→バッチ→指示→自律への道
AIに「自分で学習させたい」。
でも、いきなり自律学習を実装するのは危険です。誤情報を学習したり、偏った知識に偏重したり...制御不能になるリスクがあります。
この記事では、段階的にリスクを管理しながらAIの学習機能を進化させる設計を紹介します。私たちのプロジェクトで実際に採用している4フェーズモデルです。
1. なぜ段階的に進めるのか
いきなり自律学習の危険性
graph TD
Day1[1日目: 自律学習機能作成] --> Day3[3日目: Wikipedia自動クロール]
Day3 --> Week1[1週間後: 変な情報を学習]
Week1 --> Month1[1ヶ月後: 制御不能]
Month1 --> Death[💀 制御不能]
style Death fill:#ffcccc,stroke:#ff0000,stroke-width:2px
段階的実装のメリット
graph TD
Phase1[Phase 1: 質問応答] -->|動作確認OK| Phase15[Phase 1.5: バッチ投入]
Phase15 -->|品質確認OK| Phase2[Phase 2: 指示学習]
Phase2 -->|検証機能OK| Phase3[Phase 3: 自律学習]
Phase3 --> Success[✅ 制御可能な状態]
style Success fill:#ccffcc,stroke:#00ff00,stroke-width:2px
2. 4フェーズモデル
全体像
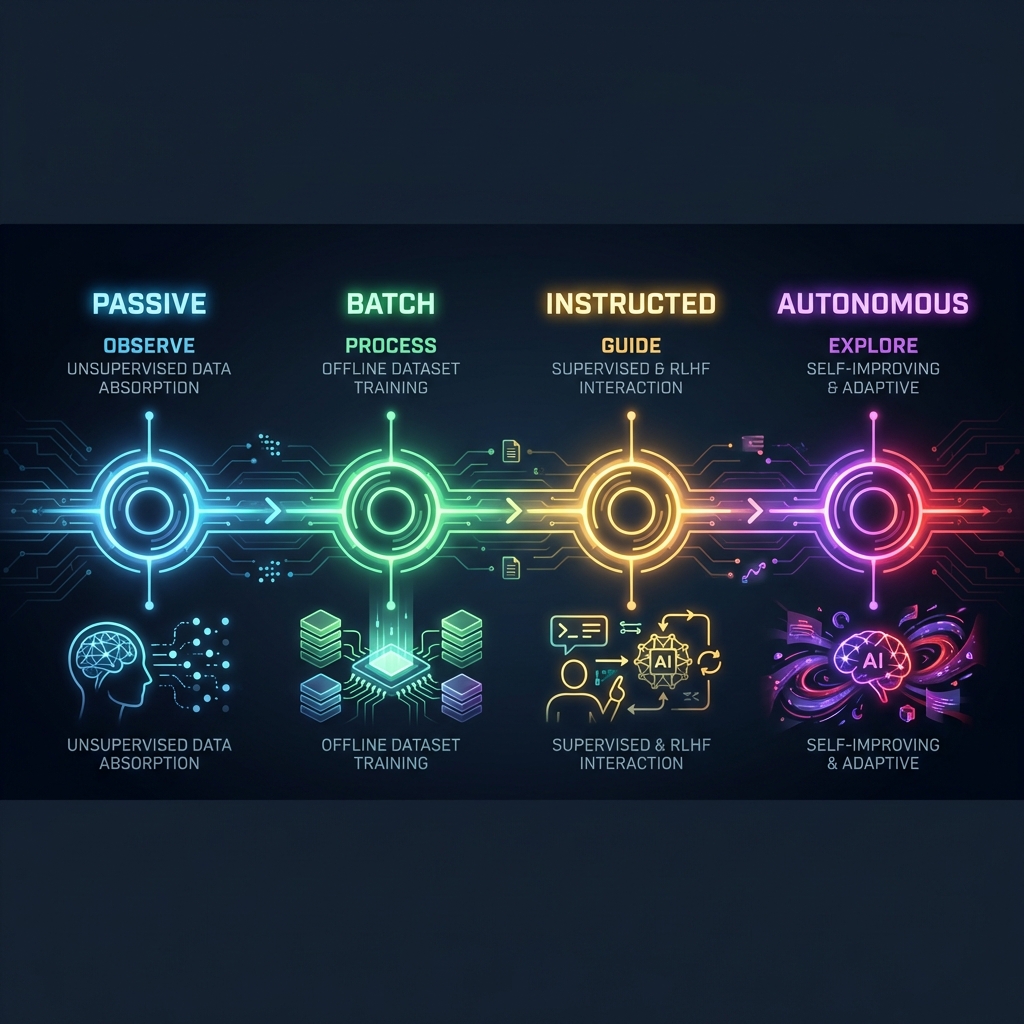
学習の進化は「受動」から「自律」へと段階的に進みます。フェーズが進むほどAIの自律性は高まりますが、同時にリスクも高まるため、慎重な設計が必要です。
3. Phase 1: 受動学習
概要
ユーザーからの質問に答える基本機能。AIから能動的に学習することはしません。
やること
sequenceDiagram
participant User as ユーザー
participant AI as AI
participant Wiki as Wikipedia
participant Neuron as Neuron(記憶)
User->>AI: 「夏目漱石について教えて」
AI->>Wiki: 検索
Wiki-->>AI: 情報取得
AI->>AI: 情報整理
AI->>Neuron: 保存
AI-->>User: 回答
特徴
| 項目 | 内容 |
|---|---|
| 学習タイミング | ユーザーの質問時のみ |
| 情報ソース | Wikipedia, Wiktionary等(限定的) |
| 品質管理 | 人間がリアルタイムで確認可能 |
| リスク | 低い |
必要なコンポーネント
- 意図解析(IntentParser)
- 知識ソース接続(KnowledgeSource trait)
- 記憶保存(Neuron)
この段階の目標
「正しい質問に正しく答えられる」状態を作る
基本的な応答品質が安定していないと、次のフェーズに進めません。
4. Phase 1.5: バッチ学習
概要
Pythonスクリプト等で構造化データを一括投入し、知識のベースラインを構築します。
なぜバッチ学習が必要か
Phase 1だけでは、ユーザーが一つずつ教える必要があり、効率が悪すぎます。10万語の語彙を教えるには膨大な時間がかかります。
データの投入順序
難易度順に進めます:
| 順序 | データ | 構造 | 量 | 難易度 |
|---|---|---|---|---|
| 1 | JMDict | 構造化 | 10万語 | 簡単 |
| 2 | Wikipedia基礎 | 半構造化 | 数千記事 | 中程度 |
| 3 | 青空文庫メタ | 構造化 | 数万作品 | 中程度 |
| 4 | 青空文庫本文 | 非構造化 | - | 難しい(将来) |
段階的投入の重要性
一気に10万語を投入すると、何か問題が起きたときに原因の特定が困難になります。 100語 → 1,000語 → 10,000語 と段階的に投入し、各段階で検証を行うことが安全への近道です。
各段階での確認項目
- Neuronに正しく保存されているか
- 重複エントリが発生していないか
- 検索パフォーマンスに問題ないか
- メモリ/ディスク使用量が許容範囲か
この段階の目標
「基礎的な語彙と知識が揃った」状態を作る
5. Phase 2: 指示学習
概要
外部からの指示により知識を獲得する機能。「これ覚えて」と言われて学習します。
2つのパターン
パターン1: Python連携
大量の専門知識などを注入する場合に使用します。
# Pythonスクリプトから知識を投入
def teach_yui(topic: str, content: str):
response = requests.post(
"http://localhost:3000/api/learn",
json={
"topic": topic,
"content": content,
"source": "python_script"
}
)
return response.json()
# 前処理したデータを投入
teach_yui("量子コンピュータ", "量子ビットを用いた計算機で...")
パターン2: ユーザー指示
対話の中で特定の知識を教える場合に使用します。
ユーザー: 「量子コンピュータについて覚えて」
AI: (外部ソースを検索し、情報を整理して保存)
AI: 「量子コンピュータについて学習しました!」
リスクと対策
| リスク | 対策 |
|---|---|
| 指示内容自体が誤り | 信頼度スコアリング |
| 悪意のある指示 | ソース検証 |
| 重複学習 | 既存知識との照合 |
この段階の目標
「外部から知識を注入できる」状態を作る
6. Phase 3: 自律学習
概要
AI自身が「気になること」を自律的に調べ、知識を拡張します。
機能
- 関連ワード探索: Wikipediaの関連リンクを辿り、知識グラフを自動的に広げます。
- 好奇心駆動学習: 会話で出てきた未知の概念を自動調査し、「気になる」リストを消化します。
- 知識の深化: 浅い知識を検知して自動で補完します。
リスクが高い理由
自律学習は「誤情報の学習」「エコーチェンバー(知識の偏り)」「制御不能(無限学習)」といった深刻なリスクを伴います。
必須のリスク対策
マルチLLM合議(ファクトチェック)
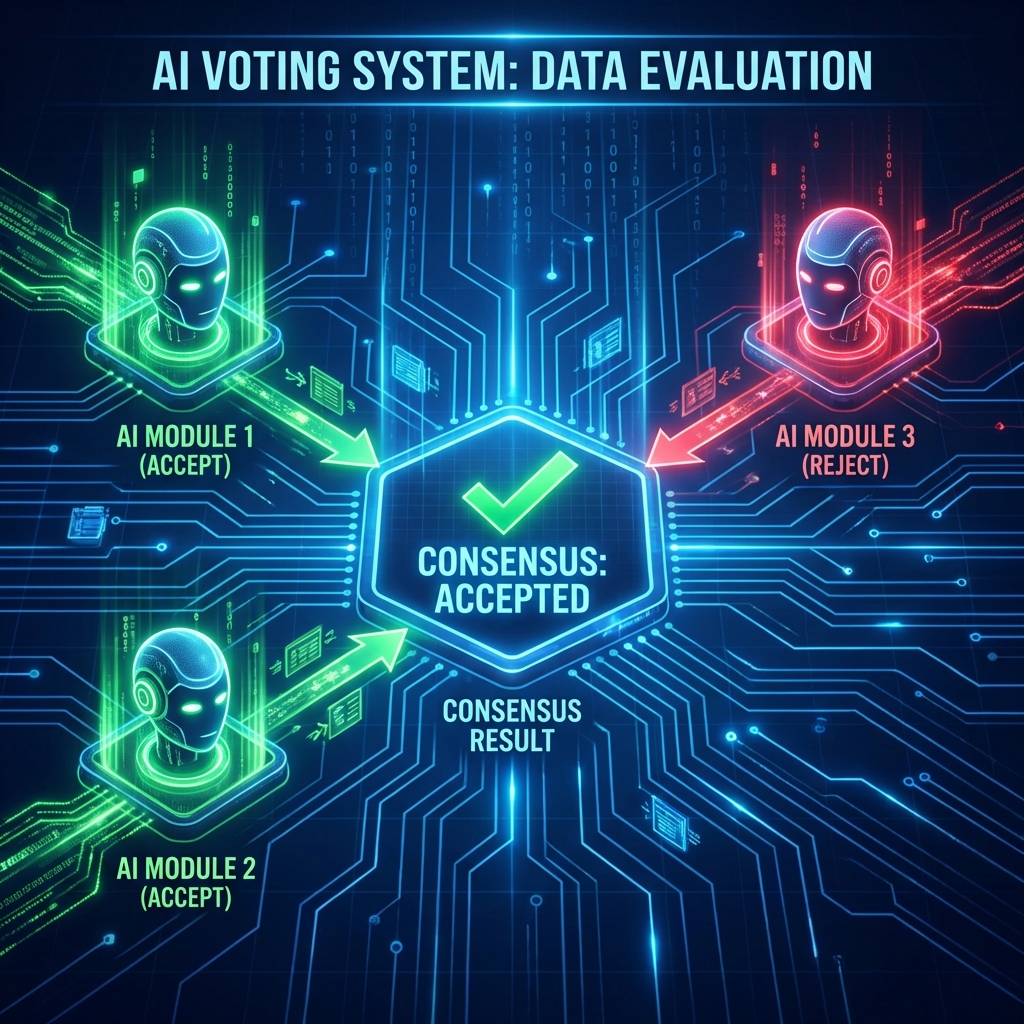
外部から取得した情報(「〇〇は△△である」)を鵜呑みにせず、複数の異なるLLMにその情報の真偽を問います。 多数決(例えば3台中2台が「正」とする)で採用するかどうかを決定することで、誤情報を学習するリスクを大幅に低減できます。
エコーチェンバー対策
- 複数ソースからの取得: 単一ソースに依存しない
- 多角的検証: 異なる視点のLLMで検証
- 偏り検知: 特定分野への知識偏重を検知
信頼度スコアリング
struct LearnedKnowledge {
content: String,
source_trust: TrustLevel, // ソースの信頼度
consensus_score: f32, // LLM合議の一致度
consistency_score: f32, // 既存知識との整合性
final_confidence: f32, // 最終信頼度
}
この段階の目標
「自律的に知識を拡張しながら、品質を維持できる」状態を作る
7. フェーズ移行の判断基準
Phase 1 → Phase 1.5
- 応答品質が安定している
- 意図解析が正しく動作している
- デバッグ・問題特定ができる状態
Phase 1.5 → Phase 2
- バッチ投入が完了(目標量)
- Neuronの状態が健全
- 検索パフォーマンスが許容範囲
Phase 2 → Phase 3
- 指示学習が正しく動作している
- マルチLLM合議が実装済み
- ファクトチェック機能が検証済み
- エコーチェンバー対策が設計済み
8. まとめ
| Phase | 名称 | 内容 | リスク |
|---|---|---|---|
| 1 | 受動学習 | 質問に答える | 低 |
| 1.5 | バッチ学習 | 構造化データ一括投入 | 低 |
| 2 | 指示学習 | 「覚えて」で学習 | 中 |
| 3 | 自律学習 | 自分で調べて学習 | 高 |
急がば回れ。
各フェーズで品質を確認しながら進めることで、制御可能なAI学習システムを構築できます。
参考
この設計は私たちの「Yui AI」プロジェクトで実際に採用しているものです。
※個人開発のAIプロジェクトでの実践をもとに作成しました